TL;DS - 21 fairness definition and their politics by Arvind Narayanan
These are the notes from the Tutorial: 21 fairness definition and their politics given at ACM FAT* (Fairness, Accountability and Transparency) Conference in 2018 by Arvind Narayanan who is associate professor of computer science at Princeton University.
- Predictive accuracy: Frequent assumption is decision maker’s goal is to maximize accuracy subject to fairness constraint
Statistical bias vs Societal bias
- Statistical bias: Difference between an estimator’s expected value and the true value. It is a surprisingly an adequate fairness criterion among technologists/computer scientists. Argument is that “I have built a model that summarizes the data correctly, if the data is biased it is not the algorithm’s fault.” - Faults with Statistical Bias and the argument is that it doesn’t account for errors or distribution of errors. Consider two distributions:
- All the values are same as the expectation E
- Another distribution has expectation E
- Both have same statistical bias.
- Another fault is that data biases are inevitable in real world, you must design algorithm to account for them.
- We need to reframe the problem and move away from mathematical correctness and thus the real challenge is how we make algorithmic systems support human values
Various definitions
Group Fairness
- Do outcomes systematically differ between demographic groups (or other population groups). Became a heated topic after pro-publicas analysis of COMPAS
Impossibility Theorem
- If an instrument satisifies predictive parity, but the prevalence differs between the groups, the instrument cannot achieve equal false positive and false negative rates across the groups.
- Problem we consider (Setting up environment for the talk) is of binary classification | TN | FP | | FN | TP |
- Different people have different perspectives on what they expect from the binary classifiers (From debate between ProbPublica vs Northpointe)
- Different stakeholders and their views:
- Decision-maker = how many will recidivate of those who I’ve labeled positive = (TP/(TP+FP)) = Pos Predictive value
- Defendant = False Positive rate
- Society = Is the selected set demographically balanced? = Demography
- Equalize X amongst different groups = Y
- Selection probability gives Demographic parity (disparate impact) [1]
- Pos. predicitive value gives Predictive Parity [2]
- Neg. predictive value
- False positive | negative rate gives Error rate balance
- Accuracy gives Accuracy equity
We can choose any three but we cant have all the three same for different groups with different prevalence rates. Chouldechova’s impossibility theorem states that we can choose any three and reach the same impossibility result.
Thus, it is suggested we use two to measure fairness. Chouldechova suggests to use FPR and FNR. But even that might not be possible. Because the impossibility theorem does has very minimum assumptions and does not even consider that you are treating individuals equally.
Different metrics matter to different stakeholders, there is no “right” direction.
For hiring or any other metric in real-life challenge is how do we measure true positives. What standards do we use?
Individual Fairness
Generally impossible to pick a single threshold (basic version of individual fairness) for all groups that equalize both FPR and FNR, assuming scores are calibrated.
What do people prefer? Should everyone be treated same is defined by same thresholds or by same statistics after using different thresholds.
Interesting Link - Sharad Goel
Fairness and Utility
Algorithmic Decision Making and the Cost of Fairness
Provocations
Tradeoffs in selecting a metric
To satisfy even a single fairness criterion (say equal FPR), we have to sacrifice a little in terms of utility (public safety and/or number of defendants released)
- Between different measures of group fairness
- Between group fairness and individual fairness
- Between fairness and utility
Lot of work happening in technical community around this is happening without the availability of a moral framework. The approach has been to design a loss function and utility function and optimize them. This seems a bit incoherent, like counting apples and fairness, and concluding that the answer is 7.3 [a random number].
Fairness in Machine Learning: Lessons from Political Philosophy
Department of Computer Science: Reuben Binns
Much of this applies to human decision making as well. Tensions between different things different stakeholders might want.
Non-obvious ways in which this might affect us - police search of a vehicle can be seen as a prediction of the presence of contraband in that vehicle. Thus, here as well we can see how this varies for different demographic groups and here as well impossibility theorem applies.
Tensions between disparate treatment and disparate impact
Read Ricci v. DeStefano - Wikipedia
Tension between disparate treatment and disparate impact. Different groups have to be treated differently to maintain fairness. Humans deal with it on case-by-case basis. But this is not scalable for algorithmic decision making.
New complexities
System that uses protected attributes for training but not for prediction. [1711.07076] Does mitigating ML’s impact disparity require treatment disparity?
Ineffectiveness of Blindness
[1610.02413] Equality of Opportunity in Supervised Learning. Quantifies the ineffectiveness of blindness, in ML algorithms. Shows blindness in ML is ineffective. Reasons:
- ML bias is “just” a side effect of maximizing accuracy
- ML is much better at picking up proxies on data
Unacknowledged affirmative action
Big Data’s Disparate Impact by Solon Barocas, Andrew D. Selbst :: SSRN
Barocas said “What is the Problem to Which Fair Machine Learning is the Solution? | Solon Barocas | AI Now 2017”
Pervasive issue: Prevalence is different amongst groups.
Why is prevalence different? Two common reasons
- Measurement bias. E.g. estimating crime using rearrests rather than recidivism. Thus we employ correction using algorithms. This can be seen as a fairness intervention.
- Historical Prejudice. E.g. poverty/crime/unemployment cycle. Correcting for this can be seen as an affirmative action.
When we see a dataset, it might be extremely difficult to find how much the difference in prevalence is because of measurement bias and how much is it because of historical prejudice.
Common Pitfalls for Studying the Human Side of Machine Learning
The big demographic parity debate
Third reason for different prevalence is that there might be intrinsic differences in different groups of people.
Demographic parity assumes no intrinsic differences between the groups.
Thus, an alternative approach is - we separate the data problem and algorithmic problem. Solving data problem means mitigating measurement bias. And solving algorithmic problem means minimizing bias w.r.t input data.
Counterpoint to this alternative approach is - there is no way to solve the data problem. Authors of An algorithm for removing sensitive information: application to race-independent recidivism prediction say that in criminal justice context, there is noted dearth of information with which to correct systematic measurement error in arrest data and there is evidence for this. Thus, if we cant possibly solve the data problem, we should assume as a hypothesis that there are no intrinsic differences between the demographics and thus use demographic parity.
Other definitions
Individual fairness
Similar individuals (based on a metric that defines how similar two given individuals are in the context of a decision-making task) should be treated similarly. The idea came from - Fairness through Awareness by Dwork et. al., more details can be found in this video - Emerging theory of algorithmic fairness
Provocations as a result of this definition
Can a randomized classifier be fair?
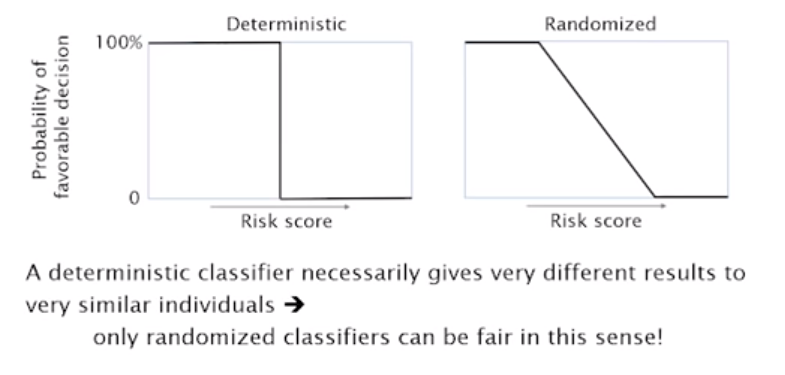
A deterministic classifier necessarily gives very different results to very similar individuals, thus only randomized classifiers can be fair in this sense.
Should we trust decision-maker’s intentions?
View 1: decision-makers are callous if not malicious; compliance with the fairness definition is the only thing preventing discrimination or misbehavior.
View 2: decision-maker fundamentally has god intentions, and the fairness mechanism helps the decision-maker avoid any unintentional discrimination.
How to foster democratic debate on fairness (metrics) ?
The paper says that “the similarity metric is .. public and open to discussion and continual refinement.”
But today, we are nowhere close to this and incentives favor secrecy compared to openness.
Process Fairness
How fair is the process? (In contrast with how fair are outputs as seen earlier). Fairness value of a predictive feature: percentage of the survey respondents who consider it fair to use (with various stipulations).
Very little work in this direction by computer scientists. One of it The Case for Process Fairness in Learning: Feature Selection for Fair Decision Making. Paper explores tradeoff between accuracy, process fairness and output fairness.
Provocations
- Can process fairness be modeled as an optimization problem or is the vocabulary of ML too limited?
- Conversely, does the inscrutability of machine learning limit the usefulness of human intuition as a guide to process fairness?
Diversity
Diversity and its relation to fairness. A really nice work describing this - Diversity in Big Data: A Review. An important consideration for ranking, selection, matching, recommendation. Various definitions are available, such as the average distance between selected items.
The key in this field is the distance function to define diversity. Under-studied problem.
Fairness for problems such as Google Translate or a Face filter learning algorithm
These definitions correspond to a different suite of problems - Representational harms. The way Kate Crawford puts in her talk - The Trouble with Bias.
There are two kinds of problems:
- Allocative harms. System withholds opportunity (e.g. hiring, criminal justice, etc.). Leads to economic harms. Discrete transaction, immediate effects.
- Representational harms. System reinforces subordination of a group (stereotyping, cultural denigration, etc.). Leads to social harms. Has diffuse, long-term effects.
Stereotype mirroring and exaggeration
Unequal Representation and Gender Stereotypes in Image Search Results for Occupations
- Mirroring: strength of stereotype exhibited by system reflects real-world data.
- Exaggeration - strength of stereotype exhibited by system is amplified compared to real-world data.
Provocation
To what extent should ML models reflect societal stereotypes.
Default view of the tech world is of the view that mirroring is correct and unbiased.
Dataset Bias
Theoretically, datasets are representative snapshots of underlying visual world. But it is easily proven false as images from different datasets are discriminable. Can we quantify this?
Cross-dataset generalization: How well does a model built on a given dataset generalize to a different dataset. Equally applicable to test (say) demographic representativeness of datasets. e.g. Train a face recognition model on one dataset and test on others.
Bias in Representation Learning
Consider words and images represented as vectors. Multiple papers have shown that these representations are biased.
Provocation
Should dataset curators who release large datasets be required to do a bias assessment of the data?
- Analysis of representativeness and bias
- Intended and unintended bias
Should researchers who release pre-trained models/representations have similar obligations?
- Should released models be “debiased”?
Bias Amplification
Difference in the association between two labels in the training vs evaluation set. Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints
Summary
Definitions covered
- Statistical Bias
- Group Fairness
- Demographic Parity
- Equal Pos. Pred. Value
- Equal Neg. Pred Value
- Equal FPR
- Equal FNR
- Accuracy equity
- Blindness
- Individual fairness
- Equal thresholds
- Similarity metric
- Process fairness (feature rating)
- Diversity (various definitions)
- Representational harms
- Stereotype mirroring/exaggeration
- Cross-dataset generalization
- Bias in representation learning
- Bias amplification
More definitions (not covered)
- [1706.02744] Avoiding Discrimination through Causal Reasoning
- [1605.07139] Fairness in Learning: Classic and Contextual Bandits
- [1601.05764] A Confidence-Based Approach for Balancing Fairness and Accuracy
- Algorithmic Decision Making and the Cost of Fairness
Why so many definitions? [Why is that a good thing?]
- Different contexts/applications
- Different stakeholders
- Impossibility theorems
- Any overarching definitions will be inevitably be vacuous
- Allocative vs representational harms
Goal is to build algorithmic systems that further human values, which can’t be reduced to a formula.
